1. Single global mutex (Sched.Lock) and centralized state. The mutex protects all goroutine-related operations (creation, completion, rescheduling, etc). 2. Goroutine (G) hand-off (G.nextg). Worker threads (M's) frequently hand-off runnable goroutines between each other, this may lead to increased latencies and additional overheads. Every M must be able to execute any runnable G, in particular the M that just created the G. 3. Per-M memory cache (M.mcache). Memory cache and other caches (stack alloc) are associated with all M's, while they need to be associated only with M's running Go code (an M blocked inside of syscall does not need mcache). A ratio between M's running Go code and all M's can be as high as 1:100. This leads to excessive resource consumption (each MCache can suck up up to 2M) and poor data locality. 4. Aggressive thread blocking/unblocking. In presence of syscalls worker threads are frequently blocked and unblocked. This adds a lot of overhead.
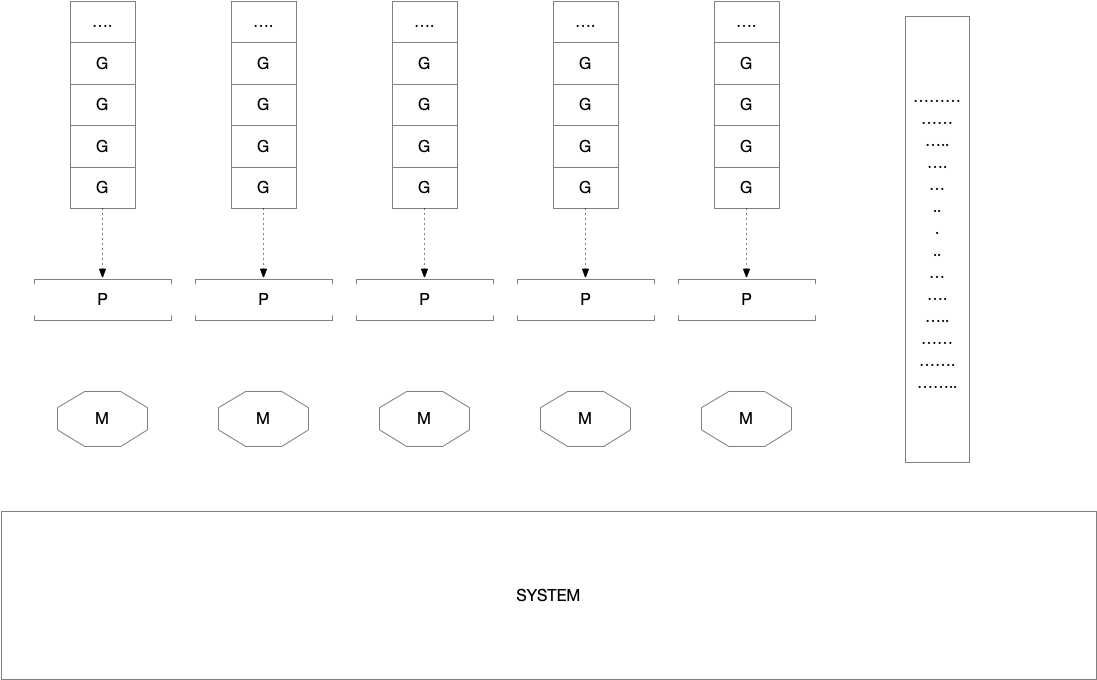
1. Introduce the P struct (empty for now); implement allp/idlep containers (idlep is mutex-protected for starters); associate a P with M running Go code. Global mutex and atomic state is still preserved. 2. Move G freelist to P. 3. Move mcache to P. 4. Move stackalloc to P. 5. Move ncgocall/gcstats to P. // work-steal工作窃取模式,仍然在全局锁下。 6. Decentralize run queue, implement work-stealing. Eliminate G hand off. Still under global mutex.
// 实现自旋替代提示锁「普通锁」。 8. Implement spinning instead of prompt blocking/unblocking. The plan may turn out to not work, there are a lot of unexplored details.
# 后进先出计划。提供公平和优雅的处理g。 1. Try out LIFO scheduling, this will improve locality. However, it still must provide some degree of fairness and gracefully handle yielding goroutines.
# 不分配内存和栈空间,直到g跑起来。对于一个新创建的g,需要下面几个函数。 这将创建to完成伴随着较低内存的负载。 2. Do not allocate G and stack until the goroutine first runs. For a newly created goroutine we need just callerpc, fn, narg, nret and args, that is, about 6 words. This will allow to create a lot of running-to-completion goroutines with significantly lower memory overhead.
# 更好的G-P。尝试入队未锁定的G到P,从上一次运行。 4. Better locality of G-to-P. Try to enqueue an unblocked G to a P on which it was last running.
# 更好的P-M。尝试执行p,在同样的M最后一次运行。 5. Better locality of P-to-M. Try to execute P on the same M it was last running.
# M限流创建。调度器创建上千哥M在毫秒之间,直到OS拒绝创建更多的thread。M必须立刻创建,最多创建k*GOMAXPROCS,后续新的M会通过定时器创建。 6. Throttling of M creation. The scheduler can be easily forced to create thousands of M's per second until OS refuses to create more threads. M’s must be created promptly up to k*GOMAXPROCS, after that new M’s may added by a timer.