If a table has a PRIMARY KEY or UNIQUE NOT NULL index that consists of a single column that has an integer type, you can use _rowid to refer to the indexed column in SELECT statements, as described in Unique Indexes.
Before 5.7.5, MySQL does not detect functional dependency and ONLY_FULL_GROUP_BY is not enabled by default. For a description of pre-5.7.5 behavior, see the MySQL 5.6 Reference Manual.
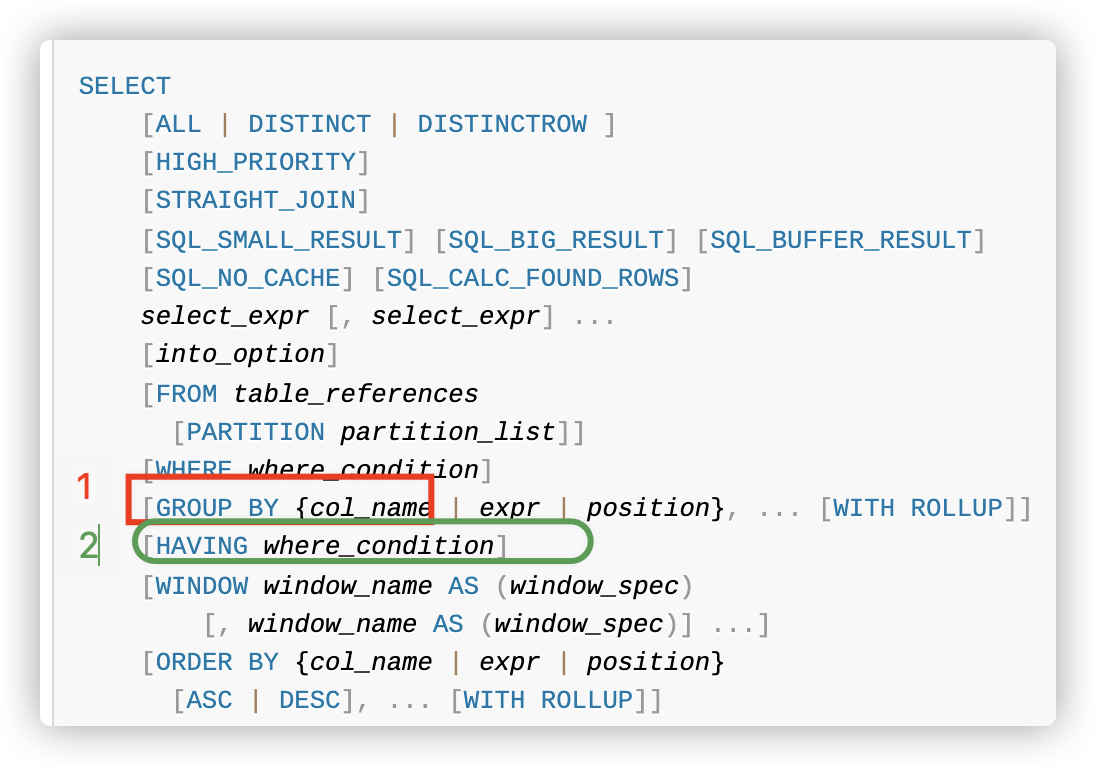
select id,name,_rowid from test.table_name having id>2groupby id; ❎ select id,name,_rowid from test.table_name groupby id where id>2; √ select id,name,_rowid from test.table_name where id>2groupby id; √